기계학습도 결국 학습이다. 이는 기계가 배워서 익히는 것을 말하는 것이다.
인공지능 초창기 1950년대 컴퓨터가 학습을 할 수 있도록 프로그래밍을 하는 것을 말한다고 한다. 하지만 최근에는 프로그램 성능을 p라고 하면 그 척도가 경험을 통해 성능이 개선되었다면 프로그램이 학습했다고 볼 수 있으며, 사례 데이터 즉 가거 경험을 이용해 성능 기준을 최적화하도록 프로그래밍하는 것이라 했다. 그리고 2012년에는 성능을 개선하거나 정확하게 예측하기 위해 경험을 이용하는 계산학이라고 정의하기 시작한다.

먼저 이해해두면 좋은 키워드를 소개하겠습니다.
- AI는 감각과 사유 그리고 적응하며, 행동을 하는 것처럼 프로그램이 동작하는 것을 말한다.
- 머신러닝은 데이터가 쌓이면 쌓일수록 성능을 개선하는 것을 말합니다.
- 딥 러닝은 머신러닝의 일부로써 ANN(Artificial Neural Network)를 쌓아가며 이를 이용해서 심층적으로 학습하는 것을 말합니다. 즉 다층으로 쌓은 레이어를 이용해서 학습합니다.
사실 인공지능 자체는 1950년대 나온 기술입니다. 인공지능에게 데이터를 주면 이를 사람들이 어려워하는 일을 척척해낼 수 있게 만들어냈습니다. (어찌보면 요즘 IT회사가 데이터회사로 가는데는 이유가 있겠죠?)
하지만 초기는 지식 기반 방식 즉 예로 들어 구멍이 2개이고 중간 부분이 홀쭉하며, 맨 위와 아래가 둥근 모양이라면 8이다 이런 식으로 분류하는 것을 자주 했습니다. 하지만 이런 방식은 가운데 구멍이 몇 개 있는 물체라고 규정해버리면 많은 오류가 생겨버리게 됩니다.

즉 이러한 부분 때문에 규정을 정의하지 말고, 데이터를 전부 나열해서 인식을 시켜서 이를 이용해서 학습하게 만드는 지식에서 기계 학습 기반으로 움직이게 됩니다.
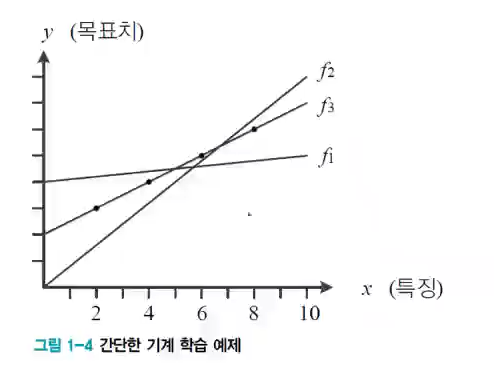
다음과 같은 예시가 있다고 가정합시다. 지금 저희는 계속 관측을 해서 8시와 10시에 어떤 값이 나올까 예측을 하려 합니다. 그럼 저희는 기반이 될 모델이 필요합니다. 여기서는 직선의 방정식이 모델이 되겠군요. 즉 저희는 모델을 만드는 과정 즉 모델링이 필요합니다.
그리고 이러한 예측을 하기 위해선 회귀와 분류 문제로 나눠서 예측을 해봅니다. 사람과 고양이를 나누는건 분류이며, 스트레스 레벨을 예측하는 과정은 회귀입니다. 즉 회귀는 목표치는 실수이며, 분류는 분류값을 반환합니다.

자 이제 다음과 같은 훈련 집합을 사용해보겠습니다. 이렇게 넣다보면
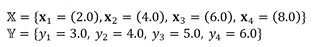
다음 과 같이 찾을 수 있을 겁니다.

이를 통해서 다음과 같은 식을 구할 수 있는데, 이 때 w는 weight 그리고 b는 bias라 합니다. 이 때 w와 b를 랜덤하게 넣고 계속 업데이트를 하면서 에러값이 작아지게 바꿉니다. 이제 만약 내가 10시에 어떤 값이 나올까를 원한다면 x에 10을 넣으면 답을 알려줍니다.
이러한 과정에서 기계 학습의 궁극 목표는 훈련 집합에 없는 새로운 샘플이 들어왔을 때 이 오류를 최소화하는 것이 목표입니다. 그리고 이 훈련 샘플에 어떤 데이터(테스트 집합이라 합니다.)가 들어올 지 모르니, 테스트 집합에 대한 높은 성능 즉 일반화 능력이 좋아야 합니다.
'Deep Learning' 카테고리의 다른 글
| [딥러닝, 수학] 확률과 통계 (0) | 2021.10.17 |
|---|---|
| [딥러닝, 수학]선형대수와 퍼셉트론 (0) | 2021.10.17 |
| [딥러닝] 간단한 기계학습 (0) | 2021.10.12 |
| [딥러닝] 인공지능과 데이터 (0) | 2021.10.12 |
| [인공지능] 특징 공간 (0) | 2021.10.12 |



